https://diane-space.tistory.com/318?category=882603
[시계열] 케라스에서 Luong 어텐션을 활용한 seq2seq2 LSTM 모델 만들기 (번역)
원문 Building Seq2Seq LSTM with Luong Attention in Keras for Time Series Forecasting | by Huangwei Wieniawska | Level Up Coding (gitconnected.com) Building Seq2Seq LSTM with Luong Attention in Keras..
diane-space.tistory.com
회귀 모델로 Seq2Seq 모델을 활용한 연구 사례가 있어 적용해 보려했으나,
난이도가 너무 높아서 다소 힘들었다.
그래서 활용 예제를 만들어 공유해보고자 한다.
만약 틀린 부분이 있으면 얘기해주기 바란다.
활용 패키지는 아래와 같으며 시계열 예측할 때 자주 나오는 AirPassengers 자료를 분해시계열을 적용하여
활용하기로 했다. 물론 관측 자료수가 적어서 성능은 안좋게 보일 것 같다.
library(forecast)
library(abind)
library(keras)
library(tensorflow)
library(kerasR)
library(scales)
data=decompose(AirPassengers)
data=na.omit(data.frame(x=data$x,seasonal=data$seasonal,trand=data$trend,random=data$random))
데이터 부분은 아래와 같이 truncate를 거쳐 증가시켰다.
truncate=function(x,train_len=24,test_len=10,cols){
in_=list();out_=list();label_=list()
for(i in 1:(dim(x)[1]-train_len-test_len)){
in_[[i]]=x[i:(i+train_len),cols]
out_[[i]]=x[(i+train_len):(i+train_len+test_len),cols]
}
return(list(X_in=abind(in_,along=0),X_out=abind(out_,along=0)))
}
train=data[1:80,]
test=data[81:nrow(data),]
means=apply(train,2,mean)
sds=apply(train,2,sd)
train=(train-means)/sds
test=(test-means)/sds
train=truncate(train,train_len=24,test_len=10,cols=c('seasonal','trand','random'))
test=truncate(test,train_len=24,test_len=10,cols=c('seasonal','trand','random'))
n_hidden=100
input_train =keras::layer_input(shape=c(dim(train$X_in)[2],dim(train$X_in)[3]))
output_train=keras::layer_input(shape=c(dim(train$X_out)[2],dim(train$X_out)[3]))
encoder=keras::layer_lstm(input_train,units=n_hidden,activation = 'swish',
dropout = .2,recurrent_dropout = .2,
return_sequences = F,return_state = T)
encoder_last_h=keras::layer_batch_normalization(encoder[[1]],momentum = .6)
encoder_last_c=keras::layer_batch_normalization(encoder[[3]],momentum = .6)
decoder=keras::layer_repeat_vector(encoder[[1]],dim(train$X_out)[2])
decoder_lstm=keras::layer_lstm(units=n_hidden,activation='swish',
dropout = .2,recurrent_dropout = .2,
return_sequences = T,return_state = F)
decoder=decoder_lstm(decoder,initial_state=list(encoder_last_h,encoder_last_c))
out=keras::time_distributed(decoder,keras::layer_dense(units=output_train$shape[[3]]))
model=keras::keras_model(inputs=input_train,outputs=out)
opt=keras::optimizer_adam(lr=0.01,clipnorm=1)
model$compile(loss='MSE',optimizer=opt,metrics=c('mae'))
model$summary()
# kerasR::plot_model(model,to_file = 'model_plot.png',show_shapes=T,show_layer_names=T)
dim(train$X_in)
dim(train$X_out)
es=keras::callback_early_stopping(monitor='val_loss',mode='min',patience = 3)
history = model$fit(train$X_in,train$X_out,validation_split=.2,epochs=500L,
verbose=1,callbacks=es,batch_size=30L)
pred=model$predict(test$X_in)
for(i in 1:dim(pred)[3]){
pred[,,i]=pred[,,i]*sds[i]+means[i]
}
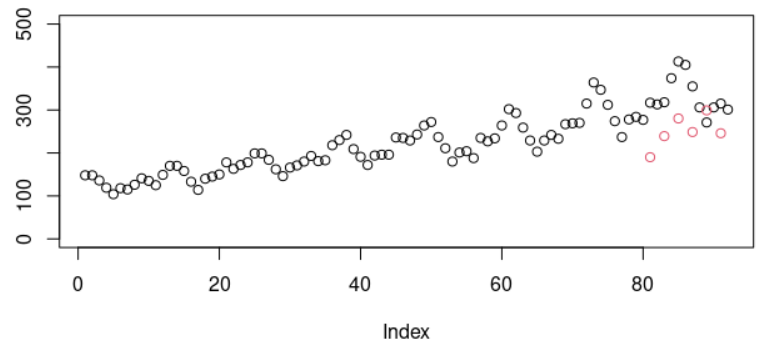
plot(data$x[1:(81+11)],ylim=c(0,500))
points(81:(81+10),apply(pred,c(1,2),sum)[1,],col=2)
아래는 단변량 코드의 결과인데 다소 아쉬운 모습을 보여준다.
train=data[1:80,]
test=data[81:nrow(data),]
means=apply(train,2,mean)
sds=apply(train,2,sd)
train=(train-means)/sds
test=(test-means)/sds
train=truncate(train,train_len=24,test_len=10,cols=c('x'))
test=truncate(test,train_len=24,test_len=10,cols=c('x'))
train$X_in=array(train$X_in,dim=c(nrow(train$X_in),ncol(train$X_in),1))
train$X_out=array(train$X_out,dim=c(nrow(train$X_out),ncol(train$X_out),1))
test$X_in=array(test$X_in,dim=c(nrow(test$X_in),ncol(test$X_in),1))
test$X_out=array(test$X_out,dim=c(nrow(test$X_out),ncol(test$X_out),1))
n_hidden=100
input_train =keras::layer_input(shape=c(dim(train$X_in)[2],dim(train$X_in)[3]))
output_train=keras::layer_input(shape=c(dim(train$X_out)[2],dim(train$X_out)[3]))
encoder=keras::layer_lstm(input_train,units=n_hidden,activation = 'swish',
dropout = .2,recurrent_dropout = .2,
return_sequences = F,return_state = T)
encoder_last_h=keras::layer_batch_normalization(encoder[[1]],momentum = .6)
encoder_last_c=keras::layer_batch_normalization(encoder[[3]],momentum = .6)
decoder=keras::layer_repeat_vector(encoder[[1]],dim(train$X_out)[2])
decoder_lstm=keras::layer_lstm(units=n_hidden,activation='swish',
dropout = .2,recurrent_dropout = .2,
return_sequences = T,return_state = F)
decoder=decoder_lstm(decoder,initial_state=list(encoder_last_h,encoder_last_c))
out=keras::time_distributed(decoder,keras::layer_dense(units=output_train$shape[[3]]))
model=keras::keras_model(inputs=input_train,outputs=out)
opt=keras::optimizer_adam(lr=0.01,clipnorm=1)
model$compile(loss='MSE',optimizer=opt,metrics=c('mae'))
model$summary()
# kerasR::plot_model(model,to_file = 'model_plot.png',show_shapes=T,show_layer_names=T)
dim(train$X_in)
dim(train$X_out)
es=keras::callback_early_stopping(monitor='val_loss',mode='min',patience = 50)
history = model$fit(train$X_in,train$X_out,validation_split=.2,epochs=500L,
verbose=1,callbacks=es,batch_size=30L)
pred=model$predict(test$X_in)
for(i in 1:dim(pred)[3]){
pred[,,i]=pred[,,i]*sds[i]+means[i]
}
plot(data$x[1:(81+11)],ylim=c(0,500))
points(81:(81+10),apply(pred,c(1,2),sum)[1,],col=2)
'통계 및 인공지능' 카테고리의 다른 글
| Symbolic Regression in R (0) | 2021.06.12 |
|---|---|
| [tensorflow]attention model (0) | 2021.06.11 |
| WaveNet in R (0) | 2021.05.02 |
| 1D-CNN & Multi input Multi output Model in R (1) | 2021.05.02 |
| R에서 ELMO 모형 사용하기 (0) | 2021.04.26 |